Garbage Collection for Systems Programmers

Let’s talk about one of the most performance-sensitive programs you run every day: your operating system. Since every speedup gives you more computer to compute with, an OS is never fast enough, so you can always find kernel and driver developers optimizing the bejesus out of their code.
Operating systems also need to be massively concurrent. Not only is your OS scheduling all userspace processes and threads, but a kernel has many threads of its own, as well as interrupt handlers to interact with your hardware. You want to minimize time spent waiting around, because again, you’re robbing your users any time you do.
Put these two goals together and you’ll find many strange and magical methods for locklessly sharing data between threads.1 Let’s talk about one of those. Let’s talk about RCU.
RCU
Say we have data that is read constantly but written rarely—something like the set of USB devices currently plugged in. In computer years this set changes once a millennium, but it can change. And when it does, it should change atomically, without blocking any readers that happen to be taking a peak.
A surprisingly simple solution is to have the writer:
-
Read the existing data from a pointer.2
-
Copy it, and apply the changes needed to make the next version.
-
Atomically update the pointer so it points at the new version.
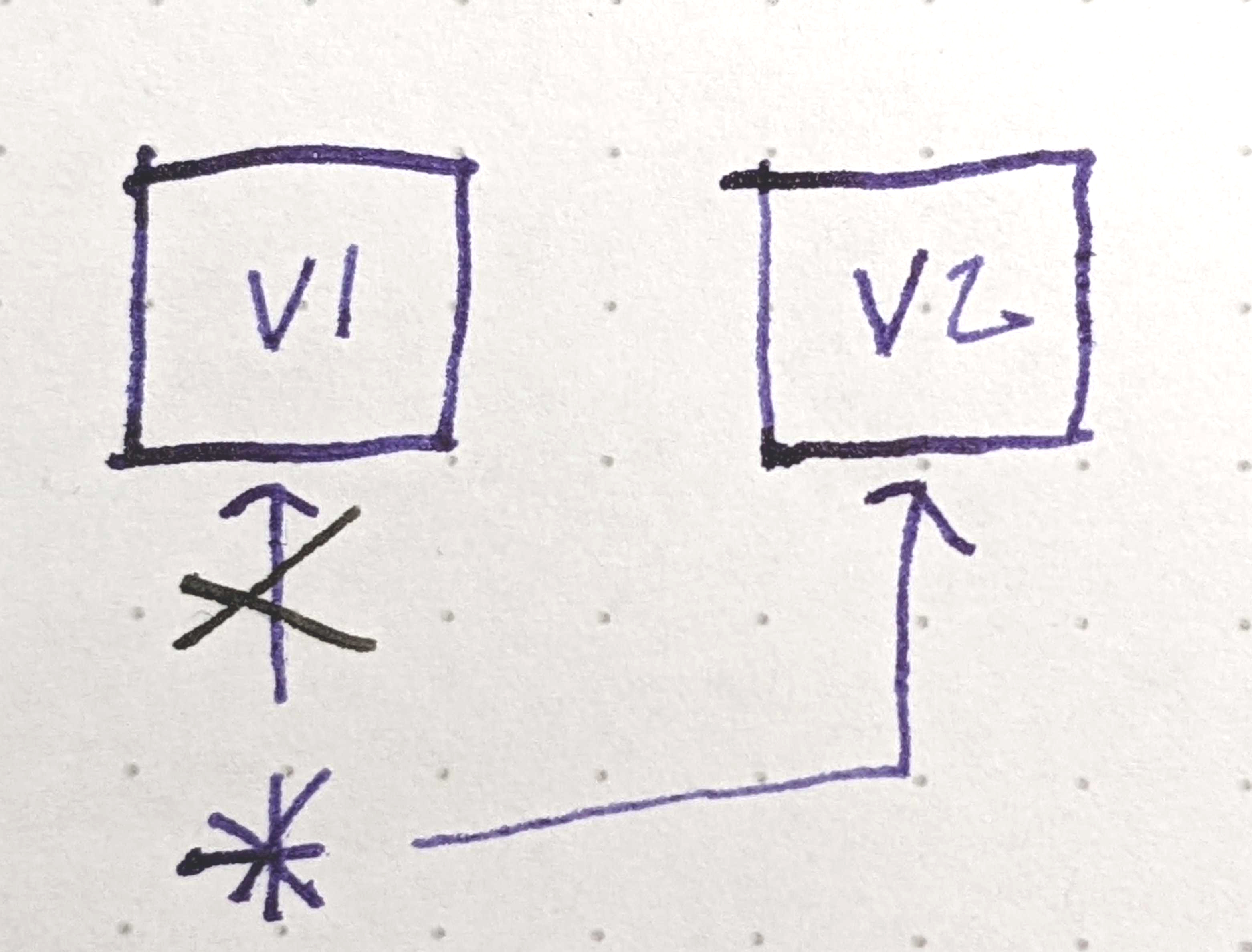
We might call this strategy, uh, Read, Copy, Update. As code, it resembles something like:
// Some big ball of state...
struct Foo {
int lots;
string o;
big_hash_map fields;
};
// ...is shared between readers and writer by this pointer.
atomic<Foo*> sharedFoo;
// Readers just... read the pointer.
const Foo* readFoo() { return shared_foo.load(); }
// The writer calls this to atomically update our shared state.
// (Wrap this in a mutex to make it multi-producer, multi-consumer,
// but let's assume the common single-producer scenario here.)
void updateFoo() {
const Foo* old = shared_foo.load(); // Read
const Foo* updated = makeNewVersion(old); // Copy
sharedFoo.store(updated); // Update
}
Awesome! It’s easy to use, it’s wait-free, and it leaks like a sieve.

Well that’s bad. Could we just delete the data?
void updateFoo() {
const Foo* old = shared_foo.load(); // Read
const Foo* updated = makeNewVersion(old); // Copy
sharedFoo.store(updated); // Update
delete old; // DANGER WILL ROBINSON
}
No, actually. Not unless you like use-after-free bugs. This is all happening locklessly,
so how do we know there aren’t still readers looking at that old version?
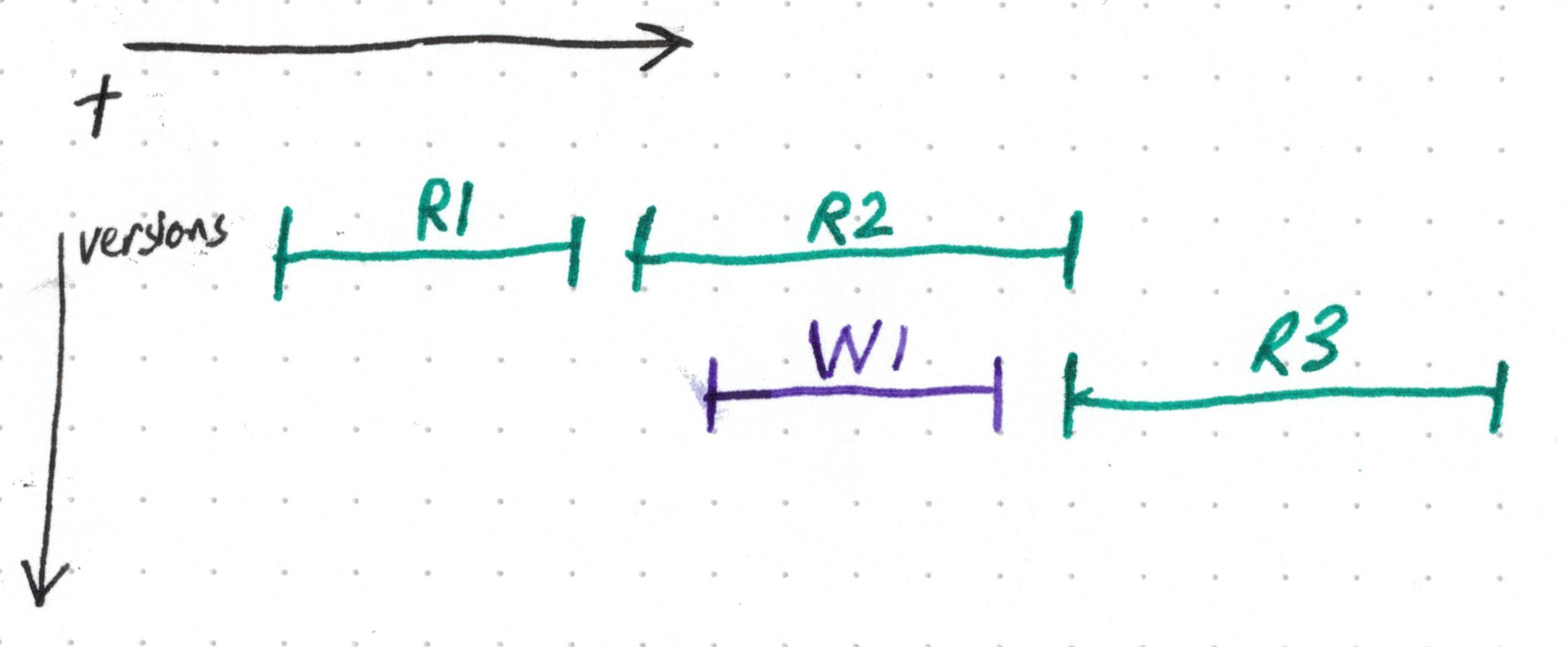
R2 in green) is still using the old version after the writer
(in purple) has updated the shared pointer. Subsequent readers (like R3) will
see the new version, but the writer doesn't know when R2 will finish!
Could readers, um, just tell us?
void someReader() {
// Tell the writer that someone is reading.
rcu_read_lock();
const Foo* f = readFoo();
doThings(f);
// Tell the writer we're done.
rcu_read_unlock();
}
This defines a sort of read-side critical section—readers still never block, but they can make the writer wait to axe any data they’re still looking at.
void updateFoo() {
const Foo* old = shared_foo.load(); // Read
const Foo* updated = makeNewVersion(old); // Copy
sharedFoo.store(updated); // Update
// Wait for current readers to "unlock"
// and leave their critical sections.
rcu_synchronize();
delete old;
}
And so,
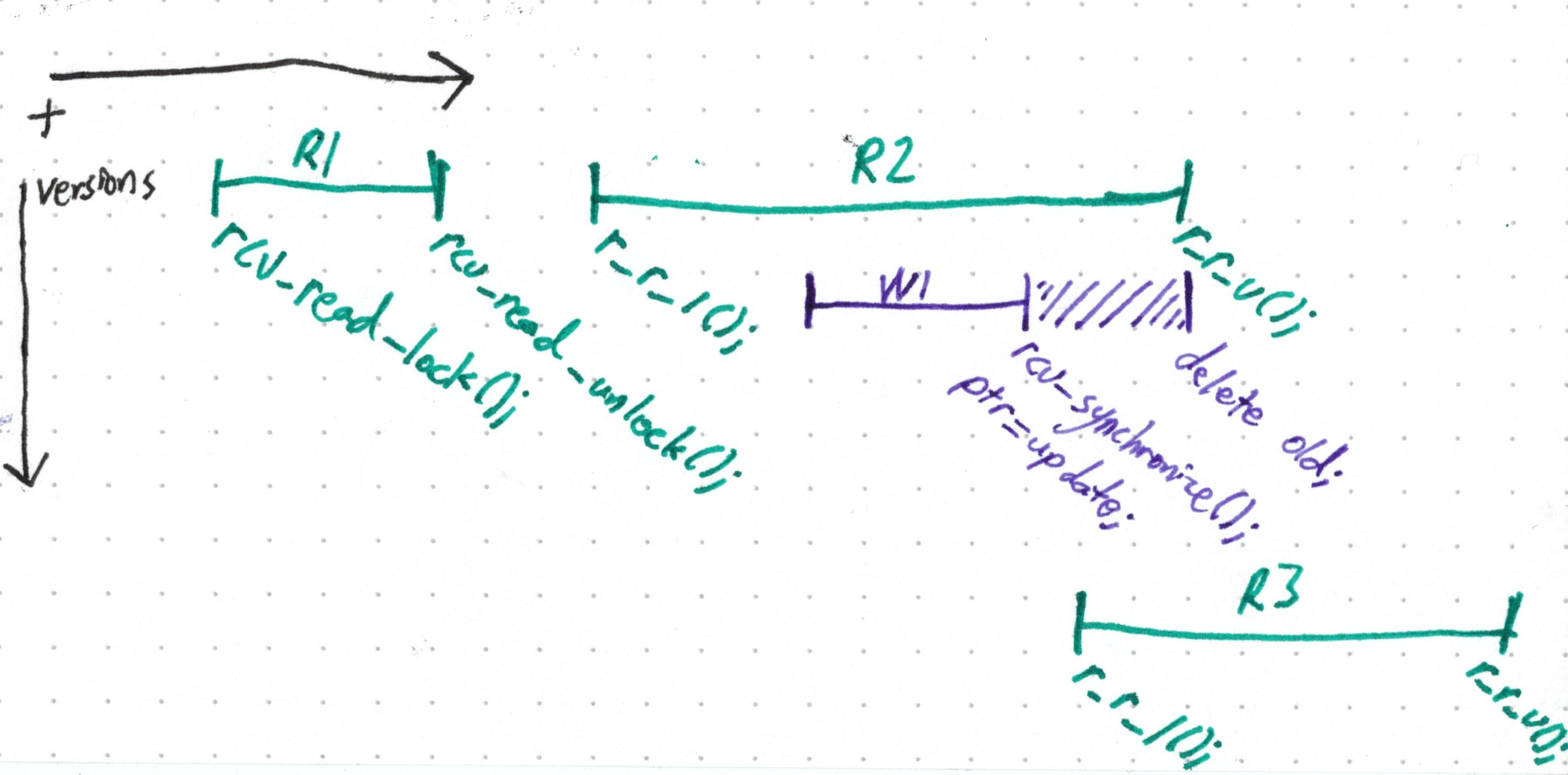
R3 gets the new version of the data, so it doesn't care about the fate of
whatever came before it.
rcu_synchronize() just needs to wait for previous readers—ones which might
be looking at old—to finish.
Normal people would be content with this solution, but kernel developers aren’t normal people. We’ve got a blocking writer now, and even though we weren’t optimizing the writer side, blocking still makes them very sad.
Suppose we don’t wait around in our update function to free the old data. Our code is correct so long as that happens eventually, right?. What if we “deferred” that?
void updateFoo() {
const Foo* old = shared_foo.load(); // Read
const Foo* updated = makeNewVersion(old); // Copy
sharedFoo.store(updated); // Update
// Our cool library can free `old` any time after
// current readers leave their critical sections.
rcu_defer(old);
}
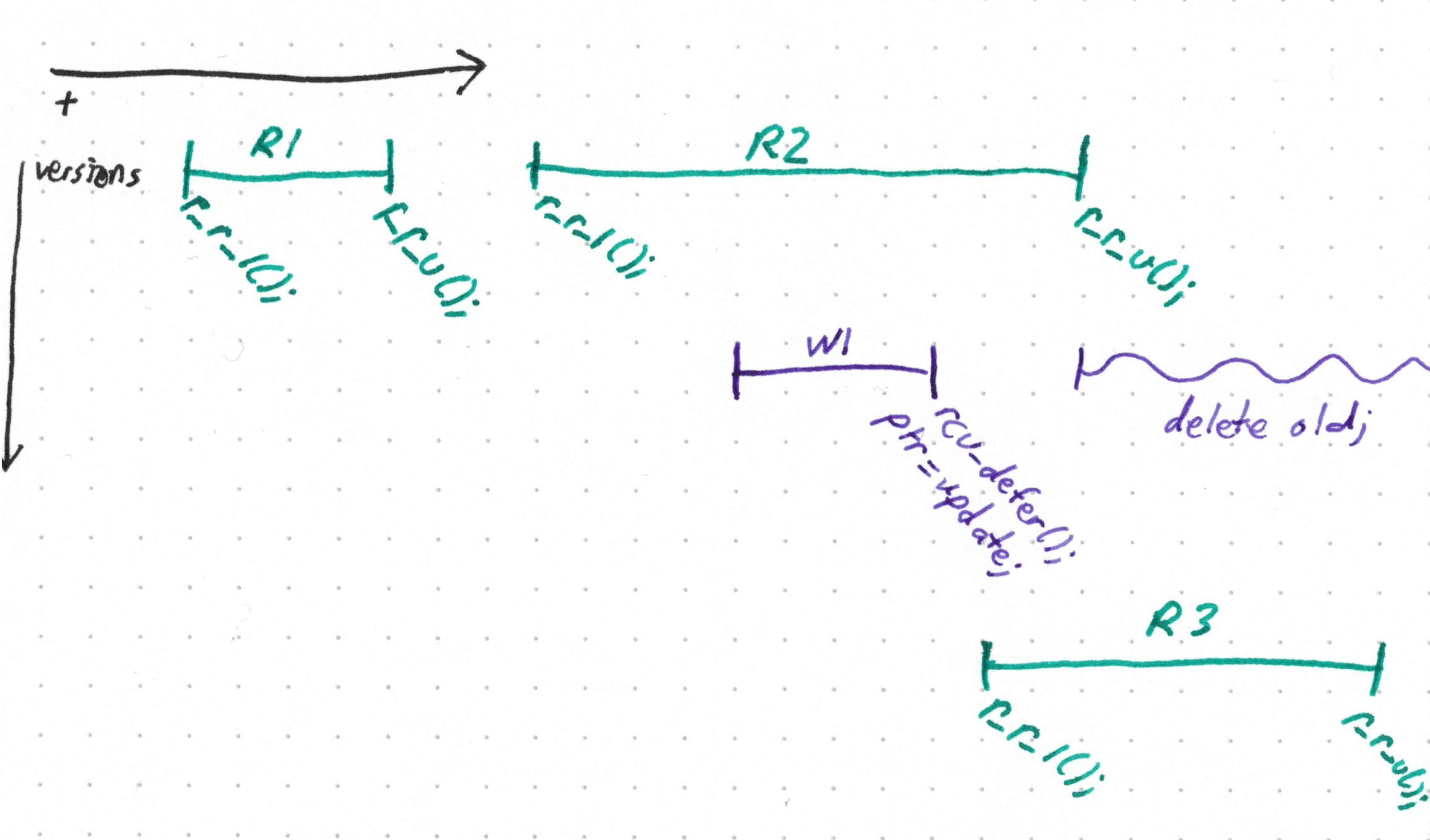
All’s well if we free old anywhere in squiggly time.
We could even have a dedicated thread occasionally sweep through all the
old, unreferenced versions of the data and…
…wait, did we just build a generational garbage collector? Of immutable data structures, no less?
Wat
This isn’t some thought experiment—RCU is very real, and very useful.
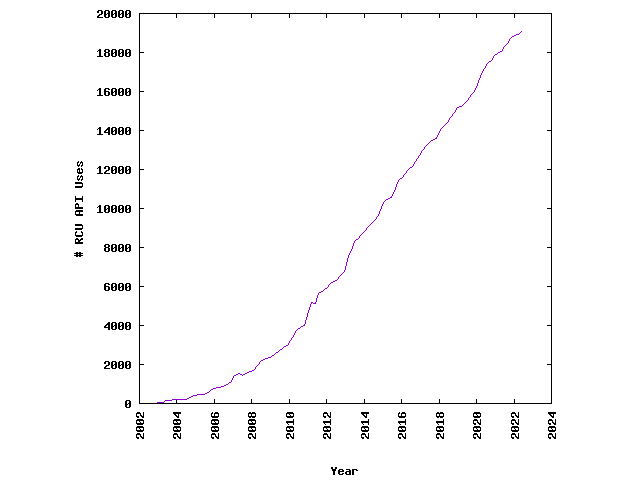
Linux uses it tens of thousands of times.
It’s provided in
Facebook’s Folly C++ library.
And in Rust it goes by crossbeam-epoch
and underpins one of the most popular concurrency libraries.
Kernel garbage collection:
At this point, some folks fire back with non-arguments about how this isn’t “real” garbage collection. Like, uh, because you manually mark the garbage! I’m not here to argue taxonomy—whatever you want to call it, RCU has the same shape as GC: memory is cleaned up eventually, based on whether it’s still in use.3 And it’s an interesting example that cuts against the prevailing wisdom that garbage collection is:
-
Slower than manual memory management
-
Takes away the fine-grained control you need when writing systems software
These arguments are clearly bullshit for RCU, which is motivated by performance and latency demands, not used as a convenience in spite of its costs. And we’re not doing any extra work, we’re just moving it out of the critical path.
…Are these arguments just generally bullshit, too?
GC is not magically slow, OR: malloc() is not magically fast
The common wisdom that garbage collectors are inherently less efficient than traditional/manual memory management falls apart pretty quickly when you look into the details of how these things actually work. Consider:
-
free()is not free. A general-purpose memory allocator has to maintain lots of internal, global state. What pages have we gotten from the kernel? How did we split those up into buckets for differently-sized allocations? Which of those buckets are in use? This gives you frequent contention between threads as they try to lock the allocator’s state, or you do as jemalloc does and keep thread-local pools that have to be synchronized with even more code.Tools to automate the “actually freeing the memory” part, like lifetimes in Rust and RAII in C++, don’t solve these problems. They absolutely aid correctness, something else you should care deeply about, but they do nothing to simplify all this machinery. Many scenarios also require you to fall back to
shared_ptr/Arc, and these in turn demand even more metadata (reference counts) that bounces between cores and caches. And they leak cycles in your liveness graph to boot. -
Modern garbage collection offers optimizations that alternatives can not. A moving, generational GC periodically recompacts the heap. This provides insane throughput, since allocation is little more than a pointer bump! It also gives sequential allocations great locality, helping cache performance.
The Illusion of Control
Many developers opposed to garbage collection are building “soft” real-time systems. They want to go as fast as possible—more FPS in my video game! Better compression in my streaming codec! But they don’t have hard latency requirements. Nothing will break and nobody will die if the system occasionally takes an extra millisecond.4
But even when we’re not on the Night Watch, we don’t want to randomly stop the world for some garbage collector, right?
Lies people believe about memory management
-
The programmer can decide when memory management happens. The wonderful thing about an operating system is that it abstracts our interactions with hardware. The terrible thing about an operating system is that it abstracts interactions with hardware. Linux, by default, does almost nothing when asked for memory, only handing it out once you actually try to use it. In our wacky world of
madvise(), memory-mapped I/O, and file system caches, there’s no simple answer to, “what’s allocated and when?” We can only hint at our intentions, then let the OS do its best. Usually it does a great job, but on a bad day, a simple pointer access can turn into disk I/O! -
The programmer knows the best times to pause for memory management. Sometimes there are obvious answers—like on the loading screen of a video game. But the only obvious answer for lots of other software is just, “whenever we’re not busy with more critical work.” Our friends
shared_ptrandArccloud our reasoning here, too—individual pieces of code holding a reference-counted pointer can’t know a priori if they’re going to be the last owner stuck with the cleanup. (If they could know, we wouldn’t need reference counting there!) -
Calling
free()gives the memory back to the OS. Memory is allocated from the operating system in pages, and the allocator often holds onto those pages until the program exits. It tries to reuse them, to avoid bugging the OS more than necessary. Not to say the OS can’t take pages back by swapping them out…
Takeaways
I’m not suggesting that all software would benefit from garbage collection. Some certainly won’t. But it’s almost 2024, and any mention of GC—especially in my milieu of systems programmers—still drowns in false dichotomies and FUD. GC is for dum dums, too lazy or incompetent to write an “obviously” faster version in a language with manual memory management.
It’s just not true. It’s ideology. And I bought it for over a decade until I joined a team that builds systems—systems people bet their lives on—that provide sub-microsecond latency, using a garbage-collected language that allocates on nearly every line. It turns out modern GCs provide amazing throughput, and you don’t need to throw that out for manual memory management just because some of your system absolutely needs to run in n clock cycles. (Those specific parts can be relegated to non-GC code, or even hardware!)
Garbage collection isn’t a silver bullet. We don’t have those. But it’s another tool in the toolbox that we shouldn’t be afraid to use.
-
To be fair, you’ll also find plenty of normal mutexes and spinlocks too. ↩
-
We could even read the pointer without the usual atomic load-acquire semantics, establishing our ordering with nothing more than the CPU pipeline’s data dependency between the pointer and the values it points to. But the tragedy of
memory_order_consumeis a story for another day. ↩ -
In an ill-advised response to, “no, the author is an idiot, RCU isn’t GC at all since quiescent-state RCU in the Linux kernel provides guarantees about when cleanup happens, and on a regular cadence” — this is an amazing optimization the kernel can make given that it has total control over when context switches occur. That doesn’t change that
call_rcu()is for moving cleanup out of the the context where it is called, and the example the kernel docs provide is… freeing data! Also look at any userspace implementation of RCU, including one by the same folks who introduced it to the kernel. You’ll find the same notions of deferring cleanup to some later time. And when your program can’t manually indicate quiescent states with no read-side critical sections, implementations use some notion of generations separated by those critical sections. ↩ -
Systems that do have hard real-time requirements are a whole different game. Have fun plumbing interrupt handlers through an RTOS, or writing drivers for FPGAs and custom circuitry. And you’re definitely not allocating anything after startup. ↩